快速通道互联(英语:Intel QuickPath Interconnect,缩写:QPI),是一种由英特尔开发并使用的点对点处理器互联架构,用来实现芯片之间的互联。英特尔在2008年开始用QPI取代以往用于至强、安腾、桌面型平台以及大部分行动型平台的处理器的前端总线(FSB)。至Intel Core i系列CPU后,QPI也被逐步应用于个人计算机上。初期,英特尔给这种连接架构的名称是“公共系统界面”(Common System Interface ,CSI),它的早期设计形态亦被称为Yet Another Protocol(YAP)和YAP+。
英特尔在发布Sandy Bridge-EP核心(Romley平台)后,也顺势公布首代QPI的改进版QPI 1.1版本。Intel于2017年发布的SkyLake-SP Xeon中,用UPI(UltraPath Interconnect)取代QPI。
背景
尽管多数时候被称作“总线”,但是QPI是一种点对点互联结构。它被设计成与超微半导体自2003年使用的超传输(HyperTransport)总线竞争。 英特尔在它下属的麻省微处理器研究中心(Massachusetts Microprocessor Design Center,MMDC)开发设计QPI,由以前曾在DEC Alpha的开发团队的成员进行。这个原先来自DEC的开发团队此前曾在康柏计算机和惠普工作,后来被英特尔挖角。而关于QPI的研究早在2004年就开始了。
QPI的首次实现是英特尔自家的Nehalem微架构。在2008年11月发售的桌面型平台处理器Core i7-900系列和X58芯片组上、在2009年3月发布服务器平台的Xeon X5500系列处理器。后来,2010年2月发布的Itanium 2处理器(核心代号“Tukwila”),也使用了QPI。
实现
QPI通常作为一个系统架构的组成部分,英特尔称之为“快速通道架构”(QuickPath architecture),这个架构的实现英特尔又称之为“快速通道技术”(QuickPath technology)。在QPI最简单的布置形态——单处理器主板上,QPI可用来将像是北桥芯片、南桥芯片的IO Hub和处理器点对点连接,像是早期Core i7-900系列与X58芯片组之间的连接。在一些更复杂的架构的例子中,多个QPI链接可将一个以上的处理器或一个以上的IO Hub甚至主板网络上的路由集线器点对点连接起来,允许各个组件通过这个网络来与另一个组件进行通信。和HyperTransport总线类似,搭载快速互联架构的处理器亦需要内置存储器控制器,支持非均匀访问架构。
每个QPI包括有两个20连线的点对点数据通道,每个通道一个发送方向,而每一方向还配备单独的时钟信号对(发送TX,接收RX),与数据信号一起形成共42个信号,如此一来达成全双工运作。每个时钟信号采用差动信号的形式发送,因此QPI的信号线共84条。20条连线被划分为四等份,每份5条连线。QPI中基本数据发送单元是80位大小的QPI数据包,每两个时钟周期完成一次一个QPI数据包的发送,在这两个时钟周期内,一个QPI数据包是分为四次发送,每次发送20比特,即一个时钟周期内发送两次。每个80位的QPI数据包内有8位用于错误纠正,8位是“链路层报头”,剩下的64位才是包含的真实有效的数据。QPI的带宽的计算上,建议计算每两个时钟周期每方向发送的有效数据量,由于QPI是双向发送的,因此每方向在两个时钟周期内都会有包含64位(8位组)有效数据的数据包的发送。尽管最初QPI仅实现四象限链接,但QPI的规格容许其它实现。每个象限可以独立使用。在高可靠度服务器上,一个QPI链接可以在降阶模式中运作。如果20+1信号中一个或多个链路失效,接口将剩余的链路以10+1或最低5+1信号来继续运作,如果时钟失效,甚至会为数据信号重新分配时钟。
最初实现四象限链路的是Nehalem架构的4核心处理器,使用完整的四象限链接QPI接口达成25.6GB/s的带宽,提供两倍于英特尔自家的X48芯片组上使用的1600MHz FSB的理论带宽。
尽管最早Core i7-900系列全面使用QPI,但其它Nehalem架构至桌面型处理器和行动型处理器,像是Core i3、Core i5以及其它Core i7系列(Lynnfield核心、Clarksfield核心以及其后续核心型号)的处理器,这些处理器因无需参与到多处理器系统上(从市场取向上也没有必要加入该特性),因此任何外部访问方式上都没有使用QPI,尽管这些处理器内部仍然使用QPI,用以连接处理器内的“Uncore”(“Uncore”指的是处理器芯片的一部分,包含存储器控制器、PCI-E控制器、以及内置GPU,乃至整个北桥),这种设计可见于基于Westmere微架构的Clarkdale核心及Arrandale核心型号上(即首代Core i3、i5)而这些系列的处理器,北桥已经移到处理器内部作为“Uncore”(或称“片上北桥”)的一部分,和处理器核心直接连接,无需再以前端总线界面连接,处理器的外部链接通过片上北桥/Uncore使用较慢的DMI(2.5GT/s至5.0GT/s的吞吐量)或PCI-e总线接口,用来连接南桥/PCH或其它形式的外部设备。Nehalem/Westmere微架构上,Uncore/片上北桥与处理器核心尚用QPI连接,而Sandy Bridge微架构以后的桌面型平台以及移动平台之处理器上则采用基于QPI派生的环形总线链路连接,同时也保证缓存一致性。
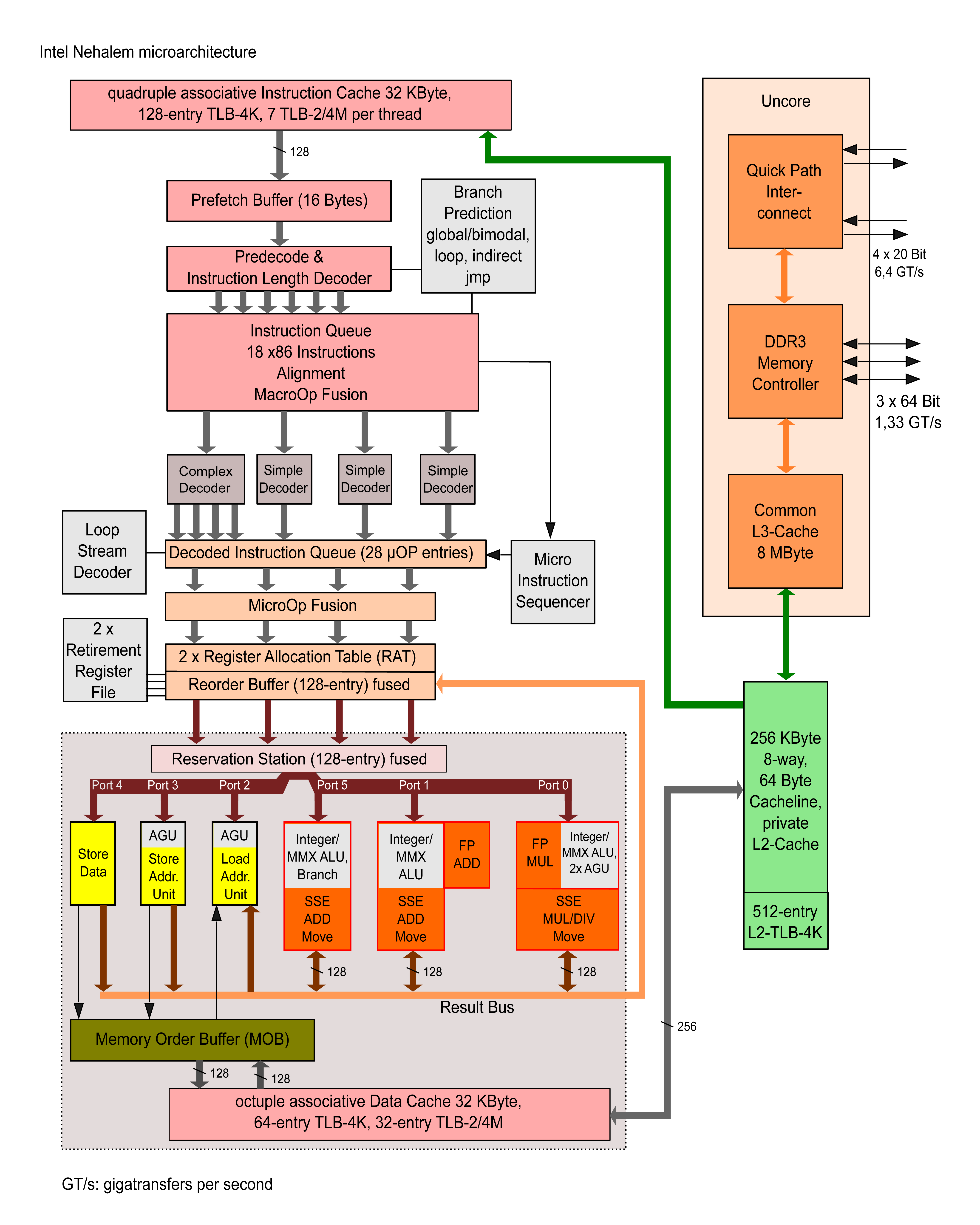
在英特尔Nehalem微架构上,QPI是其中‘uncore’的组成部分。
时脉规格
QPI的运作时脉有2.4GHz、2.93GHz、3.2GHz或4.0GHz(4.0GHz用于企业级的Sandy Bridge-E/EP核心的处理器上)。每个特定链路的时脉取决于链路终端的组件之性能以及印刷电路板上信号路径的信号特征,亦即可根据所连接组件的数据吞吐量需求自行调整时脉,提高资源利用效率。最初,非极致版本的Core i7-900系列的处理器出厂默认的QPI时脉被限定在2.4GHz。由于采用了双倍数据率技术(DDR),比特的发送在时钟脉冲信号的上升沿和下降沿都进行,因此,数据发送的实际时脉是时钟时脉的两倍。
英特尔以80位的QPI数据包封装的64位实际有效数据的发送量计数,来描述数据吞吐量和带宽。然而,由于单向发送和单向接收链路对是同步进行的,亦即全双工作业,英特尔后来将结果数字改为原来的两倍。因此,英特尔描述中,一个运作于3.2GHz时钟频率的20通道的QPI链接对(发送和接收)拥有6.4GT/s的数据发送速率,25.6GB/s的带宽,而同样通道数的QPI运作于2.4GHz时数据发送速率是4.8GT/s,带宽19.2GB/s。更通常地,根据这个定义,一个两端链接的20通道QPI每时钟周期发送8位组,每方向4位组。
带宽计算:(以运作于3.2GHz时钟频率下,吞吐量6.4GT/s)
- 3.2 GHz
- × 2 bits/Hz (双倍数据发送速率)
- × 20 (QPI连接宽度)
- × (64/80) (数据比特数/数据包比特数)
- × 2 (各向发送和接收作业同步进行)
- ÷ 8 (每字节比特数)
- = 25.6 GB/s
或:
- 6.4 GT/s
- × 2 Byte (每次传输的有效数据,64位/4次/8位一个字节=2字节每次)
- × 2 (各项发送和接收作业同时进行)
- = 25.6 GB/s
如此类推,2.4GHz或4.8GT/s、4.0GHz或8.0GT/s、2.93GHz或5.86GT/s的也可以计算出带宽。
协议层
QPI的协议定义了五层结构,分为物理层、链路层、路由层、传输层以及协议层。但是,在一些仅两节点的点对点QPI配置配置上,像是Core i7-900系列和Xeon双处理器平台(DP)系列的处理器,不需要传输层,路由层是最小最简单的两节点配置。
- 物理层:物理层包含实际接线、差分发送器和接收器、加上发送和接收的物理层单元的最低级逻辑。所谓的物理层单元是20比特的数据包分块。当20个通道全部可用时,物理层利用1个单一时钟信号边沿在20个通道上传输20比特的数据包分块,如果遇到失效/传输失败的情况时,QPI会重新配置,仅使用10个甚至只有5个通道来传输数据包分块。注意,除了数据信号以外,会有一个时钟信号从发送器发送到接收器上(这需要占用一个额外的引脚来简化时钟恢复过程)。
- 链路层:链路层负责发送和接收80位的数据包。每个数据包发送至物理层上是作为4个20比特的数据包分块的形式。每个数据包包括一个8位的CRC(循环冗余校验),由链路层发送器生成,72比特是数据包所承载的数据。如果链路层检测到一个CRC错误,发送器通过一对链路中的返回链路发回一个数据包通知发送器重发数据包。为防止接收器的缓冲器溢出,链路层还通过赊账/借记的方案来实现数据流量控制。链路层支持六种不同类型的消息,来允许更高的协议层识别数据包中主要用于保持缓存一致性非数据部分并将之拆分以掠过。在实现一些复杂的快速通道架构上,链路层可被配置成为不同类别的数据流保持数据流分离和流量控制。但是,在单处理器和双处理器平台上实现的快速通道架构,这方面的实现需要仍不明确。
- 路由层:路由层发送一个包含一个8位报头和64位数据承载的72比特单元。报头包括数据目的地和消息类型。当路由层接收到一个单元,它会检查它的路由表以确定单元是否到达目的地。如果单元已到达目的地的话,就将之传递至更高的协议层上。如果仍未到达目的地,单元将被发送到正确的向外传输QPI。在只有单一QPI架构的设备上,路由层是最小的。在更复杂的实现示例上,路由层的路由表会更为复杂、而且被定制成动态更新以避免失效的QPI链接。
- 发送层:仅有两节点的连接中,发送层并不是必须的,而且亦不会出现在这些设备上,像是Core i7。发送层可跨越QPI网络发送和接收数据,这个QPI网络由其它多个设备上的数个节点以QPI连接组成,这些设备也可能并没有直接连接(举个例子,数据可能会由一个已被插断的设备上经过),发送层会校验数据的完整性,如果数据不完整,它会要求上一个节点重新发送数据。
- 协议层:协议层发送和接收代表设备的数据包。一个典型的数据包是一个存储器缓存行。协议层也通过发送和接收缓存一致性消息的方式参与到缓存一致性的维持。
-
参见